What is Lakehouse?
- Data Architecture Platform:
- Fabric Lakehouse is a platform for organizing and working with data. It’s like a big warehouse where all types of data can be stored, managed, and analyzed together.
- Structured and Unstructured Data:
- It can handle both structured data (like tables in a database) and unstructured data (like text documents or images).
- Flexibility and Scalability:
- Fabric Lakehouse is flexible and can grow as the organization’s data needs grow. It can handle large amounts of data and adapt to changing requirements.
- Processing and Analysis:
- Organizations can use various tools and frameworks to process and analyze the data stored in Fabric Lakehouse. This allows them to gain insights and make informed decisions based on their data.
- Integration with Other Tools:
- Fabric Lakehouse works with other data management and analytics tools, providing a complete solution for data engineering and analytics needs. It seamlessly integrates with existing tools to enhance data capabilities.

Note :
The Lakehouse creates a serving layer by automatically generating a SQL analytics endpoint and a default semantic model during creation.
- Creating a Serving Layer:
- This feature automatically sets up a way to access and analyze data stored in Delta tables in the lake.
- It generates a SQL analytics endpoint and a default model for understanding the data.
- Direct Access to Delta Tables:
- Users can work directly with the data in the Delta tables without needing to set up additional layers or processes.
- This makes it easier and faster to go from collecting data to analyzing and reporting on it.
- Limitations of the SQL Analytics Endpoint:
- It’s important to know that the SQL analytics endpoint only allows reading data.
- It doesn’t support all the features of a transactional data warehouse, like writing or modifying data using T-SQL commands.

Only the tables in Delta format are available in the SQL analytics endpoint. Parquet, CSV, and other formats can not be queried using the SQL analytics endpoint. If you don't see your table, you will need convert it to Delta format.How to Interact with the Lakehouse item?
A data engineer can interact with the lakehouse and the data within the lakehouse in several ways:
- The Lakehouse explorer: The explorer is the main Lakehouse interaction page. You can load data in your Lakehouse, explore data in the Lakehouse using the object explorer, set MIP labels & various other things.
- Notebooks: Data engineers can use the notebook to write code to read, transform and write directly to Lakehouse as tables and/or folders.
- Pipelines: Data engineers can use data integration tools such as pipeline copy tool to pull data from other sources and land into the Lakehouse.
- Apache Spark job definitions: Data engineers can develop robust applications and orchestrate the execution of compiled Spark jobs in Java, Scala, and Python.
- Dataflows Gen 2: Data engineers can use Dataflows Gen 2 to ingest and prepare their data.

Multitasking with lakehouse
- Enhanced Multitasking:
- The browser tab design allows you to open and switch between multiple tasks smoothly, making data management more efficient.
- No need to switch between different windows or lose track of tasks.
- Capabilities:
- Preserve Running Operations:
- You can start an upload or data load operation in one tab and check on other tasks in different tabs.
- Running operations continue even when you navigate between tabs, so you can work without interruptions.
- Retain Your Context:
- Objects, data tables, or files you’ve selected remain open and easily accessible when you switch between tabs.
- Your data lakehouse context is always within reach.
- Non-blocking List Reload:
- The files and tables list reloads in the background without blocking your work.
- You can keep working while the list refreshes, ensuring you always have the latest data.
- Clearly Defined Notifications:
- Toast notifications specify which part of the lakehouse they’re from, making it easy to track changes and updates.
- This helps you stay organized in your multitasking environment.
- Preserve Running Operations:
How to create lakehouse in Microsoft Fabric?
Create a lakehouse
The lakehouse creation process is quick and simple; there are several ways to get started.
Ways to create a lakehouse
There are a few ways you can get started with the creation process:
- Data Engineering homepage
- You can easily create a lakehouse through the Lakehouse card under the New section in the homepage.
- Workspace view
- You can also create a lakehouse through the workspace view when you are on the Data Engineering experience by using the New dropdown menu.
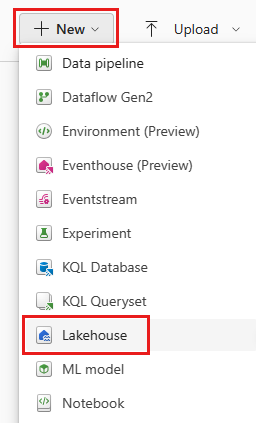
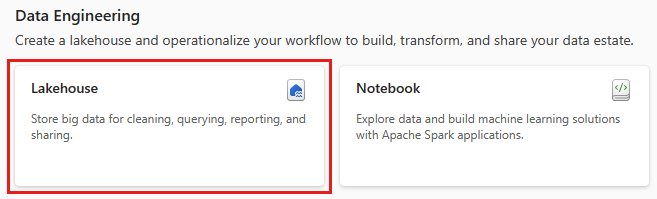
- Create page
- An entry point to create a lakehouse is available in the Create page under Data Engineering.
{kind=link}
Creating a lakehouse from the Data Engineering homepage
- Browse to the Data Engineering homepage.
- Under the New section, locate the Lakehouse card and select it to get started with the creation process
- Enter a name for the lakehouse and a sensitivity label if your organization requires one, and select Create.
- Once the lakehouse is created, you land on the Lakehouse Editor page where you can get started and load data.
How to get data into the Fabric Lakehouse?
he get data experience covers all user scenarios for bringing data into the lakehouse, like:
- Connecting to existing SQL Server and copying data into Delta table on the lakehouse.
- Uploading files from your computer.
- Copying and merging multiple tables from other lakehouses into a new Delta table.
- Connecting to a streaming source to land data in a lakehouse.
- Referencing data without copying it from other internal lakehouses or external sources.
Different ways to load data into a lakehouse
- File upload from local computer
- Run a copy tool in pipelines
- Set up a dataflow
- Apache Spark libraries in notebook code
Local file upload
You can also upload data stored on your local machine. You can do it directly in the Lakehouse explorer.

Pipelines
The Copy tool is a versatile and highly scalable Data Integration solution that facilitates seamless data movement between different sources. It empowers users to connect to diverse data sources and transfer data either in its original format or convert it to Delta tables for optimized performance.
Dataflows
If you already know how to use Power BI dataflows, you can use the same tool to import data into your lakehouse.
Notebook
You can use available Spark libraries to connect to a data source directly, load data to a data frame, and then save it in a lakehouse.
Recommendation when choosing approach to load data
| Use case | Recommendation |
|---|---|
| Small file upload from local machine | Use Local file upload |
| Small data or specific connector | Use Dataflows |
| Large data source | Use Copy tool in pipelines |
| Complex data transformations | Use Notebook code |
Fabric Lakehouse explorer
The Lakehouse Explorer page is like the main control center for everything you do in the Lakehouse environment. It’s part of the Fabric portal and lets you do things like add data to your Lakehouse, look through your data, see previews of it, and do different tasks related to your data. The page has three main parts:
- the Lakehouse Explorer section, where you do most of your work,
- the Main View where you see your data, and
- the Ribbon which has options for different actions you can take.

1. Lakehouse explorer
The Lakehouse Explorer gives you a visual way to see and work with all the data in your Lakehouse. It’s like a map that helps you find your way around and do things with your data more easily.
Table section
The Table Section in your Lakehouse shows all the managed tables in an organized way, making it easy to work with your data. You can view table details, check the table structure, access files, and perform other actions with just a click.
Unidentified Area
The Unidentified Area in your Lakehouse shows any files or folders that don’t have tables linked to them in SyMS. For example, if you upload files like images or audio that aren’t supported, they’ll go here. It helps prompt users to either remove these files or move them to the File Section for handling.
File Section
The File Section in your Lakehouse is like a storage area where raw data from different sources lands. To prepare this data for analysis, you can browse folders, preview content, load folders into tables, and perform other actions. It only shows folders, not individual files; for that, you’d use the Main View area.
2. Main view area
The main view area in the Lakehouse page is where you do most of your work with data. It shows different things depending on what you click on, and it’s where you navigate your files, preview them, and do other tasks
3. Ribbon
The Lakehouse ribbon is like a toolbar where you can quickly do important things in your Lakehouse, like refreshing data, changing settings, or adding new models. It’s a handy way to access key functions and manage your data efficiently.
Different ways to load data into a Lakehouse
There are several ways to load data into your Lakehouse from the explorer page:
- Local file/folder upload: Easily upload data from your local machine directly to the File Section of your Lakehouse.
- Notebook code: Utilize available Spark libraries to connect to data sources and load data into dataframes, then save it in your Lakehouse.
- Copy tool in pipelines: Connect to various data sources and land the data in its original format or convert it into a Delta table.
- Dataflows Gen 2: Create dataflows to import data, transform it, and publish it into your Lakehouse.
- Shortcut Creating shortcuts to connect to existing data into your Lakehouse without having to directly copy it.
- Samples: Quickly ingest sample data to jump-start your exploration of semantic models and tables.
Accessing Lakehouse’ SQL analytics endpoint
It can be an be accessed directly from the Lakehouse experience by using the dropdown in top-right area of the ribbon.Using this quick access method, you immediately land in the t-sql mode, which will allow you to work directly on top of your Delta tables in the lake to help you prepare them for reporting.