In today’s digital landscape, your cloud network is the backbone of your business operations. If you’re experiencing slow application performance, unpredictable latency, or frequent downtime, you’re not alone. Many organizations struggle with cloud networking challenges that directly impact their bottom line and customer satisfaction. This comprehensive guide will walk you through the essential strategies, concepts, and best practices to transform your cloud network into a high-performance, reliable powerhouse. Whether you’re just starting your cloud journey or looking to optimize an existing deployment, understanding the principles of network optimization is crucial for modern business success. Cloudopsnow specializes in helping organizations navigate these complex challenges with practical, proven solutions.
Understanding Cloud Network Optimization
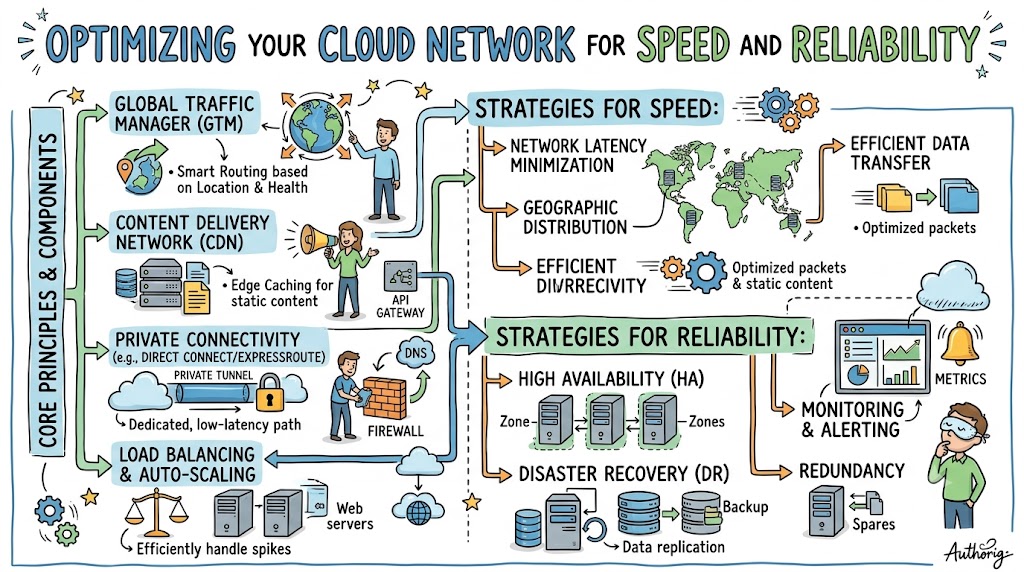
Cloud network optimization is the practice of fine-tuning your cloud infrastructure’s networking components to achieve maximum performance, reliability, and cost-effectiveness. Think of it as traffic engineering for your digital highway system. Just as a well-designed road network gets people to their destinations quickly and safely, an optimized cloud network ensures data packets travel efficiently between users, applications, and services.
The optimization process involves analyzing current performance metrics, identifying bottlenecks, implementing strategic improvements, and continuously monitoring results. It’s not a one-time fix but an ongoing discipline. Speed and reliability in cloud networking depend on multiple factors including latency, throughput, packet loss, and network congestion. Each of these elements requires specific attention and different optimization techniques.
Key Operational Concepts You Must Know
Understanding the foundational concepts of cloud networking operations is essential before diving into optimization strategies. These concepts form the building blocks of any successful cloud networking implementation and will help you make informed decisions about your infrastructure.
Direct Cloud On-Ramp Connectivity represents a paradigm shift from traditional internet-based connectivity. Services like AWS Direct Connect, Azure ExpressRoute, or Google Cloud Interconnect establish private, dedicated connections between your enterprise network and cloud provider infrastructure. These connections bypass the public internet entirely, significantly reducing latency, improving reliability, and enhancing data security. For mission-critical applications requiring guaranteed performance, direct connectivity is essential. The trade-off is higher cost, but the performance benefits often justify the investment for business-critical workloads.
Software-Defined Networking (SDN) decouples the network’s control plane from the data plane, creating a centralized, software-driven approach to managing network resources. SDN provides a unified view of your entire network fabric from a single control point, enabling dynamic traffic management and optimization. It allows intelligent routing based on real-time network conditions, preventing bottlenecks and improving user experience. Perhaps most importantly, SDN simplifies network security by enabling centrally-defined security policies that can be pushed across all connected cloud environments. The implementation of SDN represents a fundamental shift from hardware-centric to policy-centric networking.
Infrastructure as Code (IaC) has revolutionized how we manage cloud infrastructure. By defining your network configuration in code rather than manual processes, you gain consistency, repeatability, and version control. IaC enables automated provisioning, reduces manual errors, and ensures security settings are consistently applied across your entire infrastructure. This approach is particularly valuable for disaster recovery, allowing consistent recreation of entire environments in different regions or cloud providers.
Network Monitoring and Observability extend beyond traditional monitoring to provide deep insights into network behavior. Modern observability tools collect metrics, logs, and traces to create a comprehensive view of network health and performance. These tools help you identify trends, predict issues before they occur, and respond quickly to problems. Key metrics include latency, throughput, packet loss, error rates, and application performance indicators. Real-time monitoring is essential for maintaining optimal performance and quickly identifying issues before they impact users.
Load Balancing distributes incoming traffic across multiple targets, such as virtual machines or containers, ensuring no single resource becomes overwhelmed. Modern load balancers can handle SSL termination, health checks, and intelligent traffic distribution based on multiple factors like geographic location or server load. This helps achieve high availability and reliability while optimizing resource usage and maintaining consistent performance during traffic spikes.
Virtual Private Cloud (VPC) Peering enables private connectivity between different VPCs, either within the same cloud provider or across different providers. This eliminates the need for internet-based connectivity, reducing latency and improving security. Peering connections typically use the cloud provider’s private backbone network, ensuring high bandwidth and low latency. Understanding when and how to implement VPC peering is crucial for building efficient, secure multi-cloud architectures.
Content Delivery Networks (CDNs) significantly improve application performance by caching content at edge locations near users. This reduces latency and improves user experience, especially for global applications. CDNs work by distributing content across a network of geographically dispersed servers, ensuring users always connect to the nearest available location. When combined with other optimization techniques, CDNs can dramatically improve application performance.
Network Segmentation divides your network into logical segments, improving security and performance. By isolating different components of your application, you can reduce broadcast traffic and limit the blast radius of security incidents. Proper segmentation also helps with compliance requirements and simplifies network troubleshooting.
Traffic Engineering and Optimization involves intelligent routing decisions based on real-time network conditions. This includes techniques like path selection, load balancing, and traffic shaping. Advanced traffic engineering can dynamically route traffic to avoid congestion, reduce latency, and improve overall network performance. This is particularly important in multi-cloud environments where different cloud providers may have different network capabilities.
Platform Implementation vs. Culture — What’s the Real Difference?
A critical distinction that often goes unrecognized is the difference between platform implementation and organizational culture in cloud networking optimization. Many organizations focus exclusively on implementing technical solutions while neglecting the cultural aspects that determine whether those solutions will succeed.
Platform implementation refers to the actual technical architecture, tools, and processes you put in place. This includes selecting the right cloud services, configuring networks, implementing monitoring tools, and establishing automation pipelines. Technical decisions such as choosing between VPN and direct connectivity, selecting SDN solutions, or deciding on load balancing architectures are all platform implementation decisions. These choices form the foundation of your cloud networking capabilities but are only half the equation.
Organizational culture, however, determines how effectively your team can leverage these technical capabilities. A culture that embraces automation, continuous learning, and cross-functional collaboration will consistently outperform teams that resist change or operate in silos. Cloud networking is inherently complex, requiring collaboration between network engineers, security teams, application developers, and operations staff. Without a culture that supports this collaboration, even the best technical implementations will struggle to deliver results.
The real difference becomes apparent in how teams approach problem-solving. In a platform-focused organization, teams might implement monitoring tools because they’re supposed to have them. In a culture-focused organization, teams actively use monitoring data to drive improvements and have the autonomy to implement changes quickly. Similarly, infrastructure as Code is just a tool until the organization embraces the principle of treating infrastructure as software, including code reviews, version control, and continuous integration practices.
Consider how each perspective handles failure. A platform-focused approach might simply add redundancy to address failures. A culture-focused approach investigates why the failure occurred, implements root cause fixes, and shares learnings across the organization. This cultural approach to continuous improvement is what separates average cloud networking teams from exceptional ones. It requires psychological safety, where team members feel comfortable reporting issues and suggesting improvements without fear of blame.
Another crucial cultural difference is the willingness to challenge assumptions and conventional wisdom. Cloud environments evolve rapidly, and what worked last year may no longer be optimal. Teams with a healthy culture regularly re-evaluate their networking choices, question existing patterns, and experiment with new approaches. They understand that cloud networking optimization is a journey, not a destination.
Training and skill development also reflect the culture versus platform distinction. A platform-focused approach might simply ensure team members have access to training materials. A culture-focused approach creates an environment where continuous learning is encouraged, experimentation is supported, and knowledge sharing is rewarded. This might include regular tech talks, pair programming, or dedicated time for learning and experimentation.
Real-World Use Cases of Modern Operations
Global E-commerce Platform Optimization: Consider a rapidly growing e-commerce company with customers worldwide experiencing slow load times during peak shopping seasons. By implementing AWS Global Accelerator to route traffic through the AWS global network rather than the public internet, they reduced latency by up to 60% for international users. Additionally, they deployed Amazon CloudFront for content caching at edge locations, dramatically improving page load speeds. The combination of these technologies with proper load balancing across multiple regions ensured consistent performance even during Black Friday traffic spikes. Their approach included dynamic traffic management that could reroute traffic in real-time based on regional performance metrics.
Multi-Cloud Disaster Recovery: A financial services organization required a robust disaster recovery strategy across multiple cloud providers. They implemented AWS Transit Gateway to simplify routing between multiple VPCs and on-premises networks. This provided high-bandwidth, simplified routing for multi-VPC communication while maintaining strict security controls. Their disaster recovery drills consistently achieved recovery time objectives under 10 minutes, thanks to automated failover processes and Infrastructure as Code implementations. The architecture included automated health checks and monitoring that could detect regional failures and trigger failover procedures without manual intervention.
Microservices Performance Optimization: A software-as-a-service provider struggled with latency between microservices deployed across different availability zones. By implementing cluster placement groups and using Amazon RDS Proxy to manage database connections, they significantly reduced inter-service latency. The architecture included sophisticated service discovery and intelligent routing that could direct traffic based on service health and location. They also implemented Amazon VPC endpoints to ensure internal traffic remained within AWS, reducing latency and costs associated with public internet routing.
Global Content Delivery: A media streaming company needed to deliver content reliably to users across 50+ countries. Using a combination of direct cloud on-ramps and CDN services, they achieved sub-100-millisecond latency for 95% of users globally. Their architecture included multiple CDN providers for redundancy and intelligent routing based on real-time performance measurements. The implementation also included advanced video encoding and adaptive bitrate streaming to ensure smooth playback across varying network conditions. This case highlights the importance of regional placement and edge computing for global applications.
Hybrid Cloud Integration: A healthcare provider needed to maintain sensitive patient data on-premises while leveraging cloud services for analytics. By implementing dedicated connectivity via AWS Direct Connect and Azure ExpressRoute, they created a hybrid architecture that maintained low latency for data-intensive applications. This included high-performance fiber connectivity between on-premises and cloud environments, ensuring consistent performance for medical imaging applications. The architecture also included robust security measures like encryption in transit and strict access controls to maintain compliance with healthcare regulations.
IoT Data Processing: An industrial manufacturer deployed thousands of IoT sensors generating real-time data requiring immediate processing and analysis. By placing processing nodes close to the data sources using edge locations and implementing software-defined networking, they achieved sub-second latency for critical alerts. The architecture included Auto Scaling groups that could dynamically add or remove resources based on workload demands, ensuring cost-effective scaling. This implementation demonstrates the importance of network optimization in edge computing scenarios where low latency is critical.
Common Mistakes in Operations Engineering
Over-reliance on Internet-based Connectivity: Many organizations default to using the public internet for cloud connectivity, assuming it’s sufficient for their needs. This often leads to unpredictable latency, packet loss, and security vulnerabilities. The public internet operates on a best-effort basis, making it unsuitable for workloads that require consistent reliability and predictable performance. The solution is to implement direct, private interconnection solutions like AWS Direct Connect or Azure ExpressRoute for mission-critical applications, using the internet only for non-critical workloads where variability is acceptable.
Ignoring the Shared Responsibility Model: In cloud environments, security is a shared responsibility between the provider and the customer. Many organizations assume the cloud provider handles all security concerns, leaving critical vulnerabilities unaddressed. This includes securing data, access control, and operating systems. Understanding your specific responsibilities and implementing appropriate security measures is crucial. This requires careful review of the cloud provider’s security documentation and implementing complementary controls where needed, such as encryption for data at rest and in transit, identity and access management, and network security configurations.
Lack of Performance Baseline Measurement: Without establishing performance baselines, you cannot effectively measure the impact of optimization efforts. Many organizations skip this crucial step, making it impossible to quantify improvements or identify degradation. Performance baselines should include metrics like latency, throughput, error rates, and user experience measurements. These baselines should be established under normal operating conditions and regularly updated to reflect changes in your infrastructure or application workloads.
Inadequate Monitoring and Observability: Deploying monitoring tools without proper configuration and alerting often results in missed incidents and slow response times. Modern observability requires collecting metrics, logs, and traces across all network components. Many organizations focus on infrastructure metrics while ignoring application-level performance, leading to blind spots. Implementing comprehensive monitoring that correlates network metrics with application performance is essential for maintaining optimal operations.
Inconsistent Network Security Policies: In multi-cloud environments, security policies often become fragmented across different cloud providers. This creates gaps that can be exploited by malicious actors. Organizations must implement a centralized, policy-driven approach to security that spans all environments. This includes consistent identity and access management, network segmentation, and encryption policies. Implementing Policy-as-Code can help ensure security policies are consistently applied across all infrastructure components.
Neglecting Cost Optimization: While focusing on performance, organizations often overlook cost implications. Idle resources, inefficient routing, and suboptimal instance sizing can lead to excessive cloud spending. Implementing FinOps practices helps manage cloud costs effectively while maintaining performance. This includes rightsizing resources, implementing auto-scaling, and using spot instances where appropriate. Regular cost reviews and optimization should be part of your operational processes.
Manual Configuration and Management: Manual network configuration is slow, error-prone, and difficult to reproduce. Many organizations still rely on manual processes for network changes, leading to configuration drift and operational inconsistencies. Infrastructure as Code provides a solution by defining all infrastructure components in code, enabling version control and automated deployments. This approach reduces errors and enables consistent, repeatable infrastructure deployment.
Lack of Comprehensive Disaster Recovery Planning: Assuming your cloud provider will handle all aspects of disaster recovery is dangerous. You must develop and regularly test comprehensive disaster recovery plans that address potential failures across your cloud infrastructure. This includes understanding your recovery time objectives and recovery point objectives and implementing appropriate backup and replication strategies. Regular disaster recovery drills help identify weaknesses in your infrastructure and recovery procedures.
How to Become an Operations Expert — Career Roadmap
Becoming a cloud network operations expert requires a strategic combination of technical skills, practical experience, and continuous learning. This roadmap provides a structured approach to developing the expertise needed for success in this dynamic field.
Foundation Phase (Years 1-3): Start with networking fundamentals including TCP/IP, DNS, routing, and switching concepts. Gain experience with at least one major cloud provider (AWS, Azure, or GCP) and understand their core networking services. Learn Infrastructure as Code with tools like Terraform or CloudFormation. Focus on understanding the shared responsibility model, security basics, and monitoring fundamentals. Obtain foundational certifications like AWS Certified Cloud Practitioner, Azure Fundamentals, or Google Cloud Digital Leader to demonstrate your knowledge. During this phase, volunteer for networking tasks in your organization and build hands-on experience with real-world deployments.
Intermediate Phase (Years 3-5): Deepen expertise with advanced networking concepts like VPNs, direct connections, and software-defined networking. Master at least two cloud providers and understand how to design multi-cloud architectures. Develop automation skills with Python, Bash, or PowerShell, focusing on automating network configurations and operations. Implement monitoring and observability using tools like Datadog, CloudWatch, or Azure Monitor. Professional certifications become important here, including AWS Solutions Architect, Azure Network Engineer, or Google Cloud Network Engineer. This phase should include leading networking projects and mentoring junior team members.
Advanced Phase (Years 5-8): Specialize in specific areas like multi-cloud networking, security operations, or performance optimization. Master advanced concepts such as service meshes, microservices networking, and edge computing. Understand enterprise networking including SD-WAN, network segmentation, and global traffic management. Develop expertise in FinOps and cloud cost optimization. Consider advanced certifications like Professional Cloud Network Architect or Security certifications. At this stage, participate in architecture reviews, contribute to open-source projects, and speak at industry events.
Expert Phase (Years 8+): Focus on thought leadership and strategic guidance. Develop expertise in emerging technologies like AI/ML networking, zero-trust architectures, and sustainable cloud practices. Lead organizational transformation toward cloud-native networking approaches. Mentor the next generation of operations professionals. Consider contributing to industry standards or developing training materials. Expert certifications like CCIE or equivalent demonstrate peak technical expertise. At this level, focus on driving innovation and transforming how organizations approach cloud networking.
Continuous Learning and Adaptation: The cloud landscape evolves rapidly; continuous learning is essential for career growth. Subscribe to industry blogs, participate in cloud provider summits, and join professional communities. Dedicate time each week to learning new technologies and following industry trends. Specialize in emerging areas like serverless networking, IoT connectivity, or edge computing as they become relevant. Build expertise in cross-functional areas like application development and security to provide comprehensive solutions.
Soft Skills Development: Technical expertise alone doesn’t make an expert. Develop strong communication skills to explain technical concepts to non-technical stakeholders. Build project management and leadership capabilities to lead initiatives effectively. Foster relationships with vendors, partners, and other cloud professionals. Practice customer-centric thinking and business acumen to align technical solutions with business goals. These soft skills often differentiate good operations professionals from exceptional ones who can drive organizational change.
FAQ Section
What is the most important factor in cloud network optimization?
The most critical factor is understanding your workload requirements and user needs. Without this foundation, you cannot make informed decisions about connectivity options, resource placement, or performance optimization strategies. Start with a thorough assessment of your applications, user locations, and performance requirements before implementing any optimization techniques.
How does direct connectivity differ from VPN connections?
Direct connectivity like AWS Direct Connect or Azure ExpressRoute provides private, dedicated connections bypassing the public internet. This ensures predictable latency, higher bandwidth, and better security. VPN connections are more cost-effective but rely on internet infrastructure, leading to variable performance and potential reliability issues. The choice depends on your performance requirements, budget, and security needs.
What is Infrastructure as Code and why is it important?
Infrastructure as Code is the practice of managing and provisioning infrastructure through code rather than manual processes. It enables automated deployments, version control, consistency across environments, and faster recovery from failures. IaC is essential for modern cloud operations because it reduces human error and enables rapid, repeatable infrastructure deployment.
How can I measure network performance effectively?
Effective performance measurement requires a combination of tools including network monitoring solutions, application performance monitoring, and end-user experience monitoring. Key metrics include latency, throughput, packet loss, and error rates. Establish performance baselines and regularly monitor trends to identify degradation and measure improvement. User experience metrics like page load times provide a comprehensive view of performance quality.
What are the most common security mistakes in cloud networking?
The most common security mistakes include misunderstanding the shared responsibility model, using inconsistent security policies across cloud providers, failing to implement proper identity management, and neglecting to encrypt data in transit. Organizations often also overlook network segmentation, leaving their infrastructure more vulnerable to attacks and breaches.
How do I choose between single-cloud and multi-cloud networking?
Single-cloud approaches are simpler to manage but risk vendor lock-in. Multi-cloud strategies provide flexibility and resilience but introduce complexity in networking and security. The choice depends on your specific needs, including performance requirements, risk tolerance, and existing investments. Many organizations implement multi-cloud gradually, starting with one primary provider and adding others as needs dictate.
What is FinOps and how does it relate to cloud networking?
FinOps is a financial management practice for cloud environments that focuses on optimizing cloud costs while maintaining performance. In networking, FinOps involves selecting cost-effective connectivity options, right-sizing resources, and eliminating idle capacity. It requires visibility into cloud spending and continuous optimization of resource usage.
What skills are most important for cloud network operations?
Critical skills include understanding networking fundamentals (TCP/IP, DNS, routing), experience with major cloud providers, knowledge of Infrastructure as Code tools, automation capabilities, and security awareness. Additional important skills include troubleshooting, monitoring and observability practices, cost management, and cross-functional collaboration. Continuous learning is essential as the cloud landscape evolves rapidly.
How often should I review and update my cloud network configuration?
Regular reviews should occur at least quarterly, with more frequent reviews for critical systems. Key triggers for review include significant changes in application workloads, new features from cloud providers, security incidents, or performance issues. Implement continuous monitoring to identify optimization opportunities in real-time rather than waiting for periodic reviews.
Final Summary
Optimizing your cloud network for speed and reliability is a crucial journey that combines technical expertise with cultural transformation. This guide has explored the essential concepts, implementation strategies, and real-world applications that drive successful cloud networking operations. The path to an optimized cloud network begins with understanding your specific requirements and building a solid foundation of networking fundamentals. Direct connectivity options, software-defined networking, and Infrastructure as Code form the technical cornerstone of modern cloud operations.
The distinction between platform implementation and organizational culture cannot be overstated. While having the right technical tools is essential, the real success lies in fostering a culture that embraces automation, continuous learning, and cross-functional collaboration. Organizations that invest in both their technical infrastructure and their team culture consistently outperform those that focus on technical solutions alone.
The real-world use cases discussed demonstrate how optimization strategies translate into measurable business benefits, from improved user experience to cost savings and enhanced security. Learning from common mistakes helps you avoid pitfalls and accelerate your optimization journey. By following the career roadmap, you can develop the expertise needed to navigate the complex landscape of cloud networking and drive your organization toward success.